
Share article
Building the AntScout Dataset: 12 Million Images Cleaned
Introduction
I will be creating a dataset for my ant classification model, it needs to contain as many cropped images of ants as possible. See Choosing and training the best object detection model for ants for more information on the model that crops the ants.
Resources used to create this dataset
- iNaturalist
Cropped into 3.04M individually cropped ant images
Uncropped 1.23M Research grade observation images
Only research grade observations are used. Downloaded via the Open Data repository since it has the most recent and complete data. On GBIF its only 500k images. - AntWeb
193k specimen images
Antweb is not cropped since its already fully covering the ant, reducing cropping error. GBIF did not contain all the images, so I downloaded them by id. - iBOL
78k specimen images
Has a lot of duplicate specimen images from antweb, these have been deduplicated. - Museum of Comparative Zoology 60k specimen images Contains several hundred images from antweb, these have been deduplicated. These images were cropped from original, often wider specimen images, also containing labels.
Choosing the best resolution

Image attribution: “casent0922802 profile view 1” - Myrmica schencki Viereck, 1903 Collected in Czechia by California Academy of Sciences, 2000-2012 (licensed under Attribution-ShareAlike (BY-SA) Creative Commons License and GNU Free Documentation License (GFDL))
As you can see, a 368px resolution appears to capture enough detail for identification at a glance. However, the model achieves significantly higher accuracy at 512px. This suggests that while larger features like spines and hairs remain visible, the fine-grained textures and subtle anatomical nuances required for precise classification are lost or distorted at lower resolutions. These tiny details are often the deciding factor in distinguishing between closely related species, and their loss effectively introduces noise that reduces model accuracy.
Cleaning & Strategy
Before training, several data quality issues needed addressing:
- Low Res Images: Filtered out crops below 50x50px.
- Hierarchical Noise: Since some images are labeled “Lasius” (Genus) and others “Lasius niger” (Species), I used a custom hierarchical loss. This rewards the model for predicting a related child species or the parent genus instead of a binary “wrong” penalty.
- Spatial Generalization: To prevent the model from memorizing exact coordinates, I added 0.5° of location noise and randomly dropped location data (50% dropout) during training.
Dataset Cleaning & Validation
To build a reliable benchmark, I manually cleaned the validation set, ensuring it only contains high-quality field and specimen photos. The validation set is equally balanced (5 images per species) and strictly excludes any observations featured in the training set. This makes it an extremely difficult but fair test of generalization.
Dataset before and after cleaning
| Before Cleaning | After Cleaning | |
|---|---|---|
| Total Images | ~12,000,000 | 6,652,773 |
| Total Classes | 11,087 | 6,384 |
Cleaning validation set
To create a reliable validation set, I removed all genera from the validation set, and I tried to manually clean it as much as possible, to ensure that the validation set is clean and reliable.
This is more difficult than you would think, where would you draw the line of it being a good image or not? If only an antenna is visible, is that still a good image? What if the ant is blurry, or partially visible? I tried to give it a good challenge, to ensure that the validation set is of high quality.
The validation set is equally balanced, with 5 images per species. This makes it an extremely difficult validation set, but also very reliable. A big problem with this, is that a large portion of the species which only have 10 images or less, are from GBIF (Antweb mostly), which makes it so a very large portion of the validation set are specimen photos from Antweb, which are generally easier to classify than field photos, but also more difficult as they are often very similar to each other.
When evaluating the model on this dataset, it mostly just means that its good at classifying ants from Antweb, which is not the main goal, but its still a good benchmark to see how well the model performs and converges, as the different specimens from a certain species still vary a lot.
I made a simple script to by hand go through all the tens of thousands of images in the validation set, and mark the ones that are inccorect to remove them.
Heres an example of one of the few hundred pages I went through:
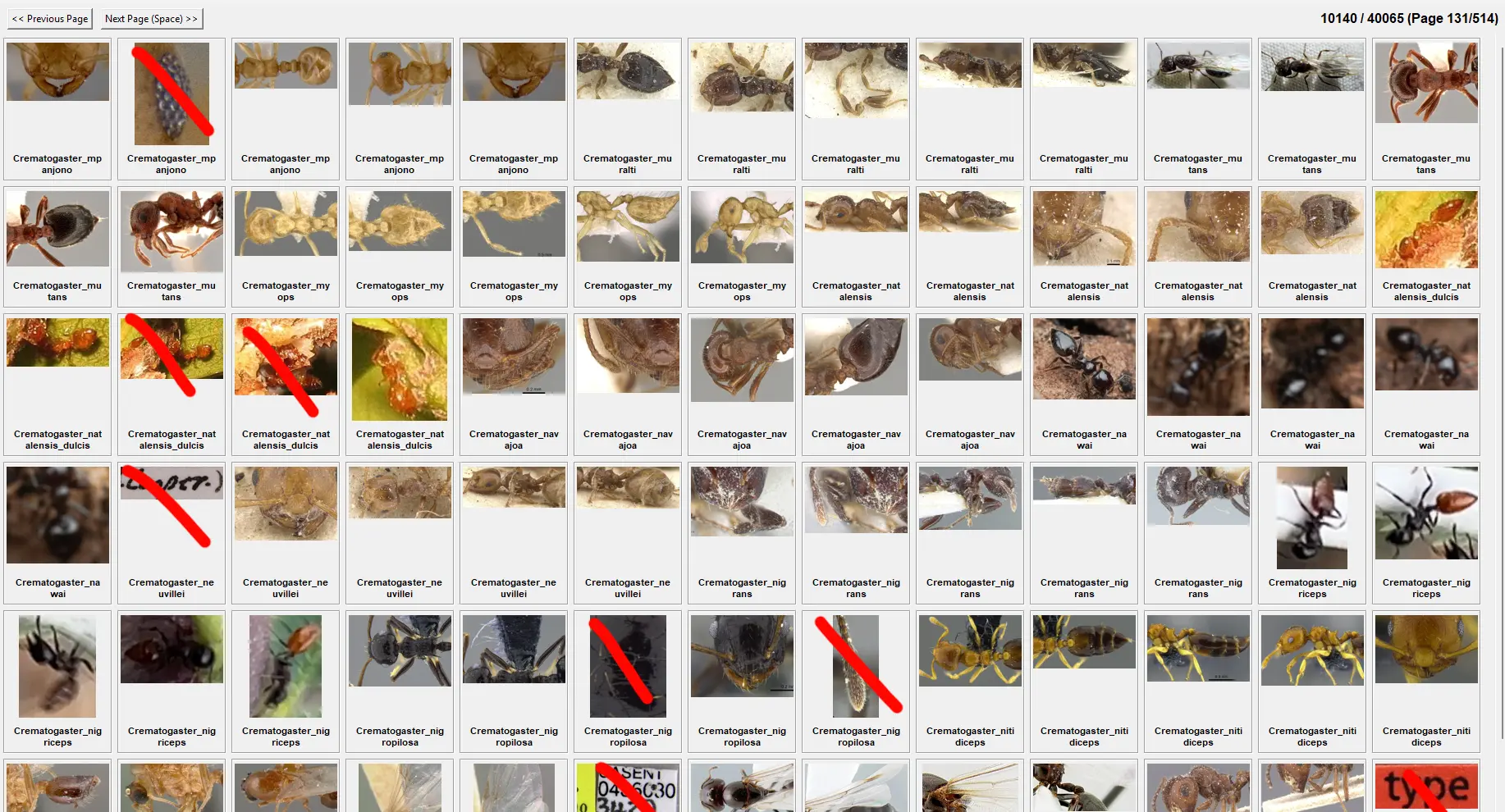
If it would get 50% on the validation set, that would mean it got half of these images (and tens of thousands of other ones like this) correct, which the model has never seen before.
Preventing data leakage
The validation set also, does not include any images that were of the same observation or source image as any of the training images, to ensure that the model is evaluated on completely unseen data. This is to prevent data leakage, where the model has seen the same image before, and is able to recognize it.
Leave a Comment